Eine Datenbank ist keine API... oder doch?
- Stefan Poss
- Tech lens
- 20. Juni 2025
Table of Contents
Zusammenfassung für Entscheidungsträger (TL;DR)
Die Frage: Kann eine Datenbank als API fungieren? Technisch gesehen, ja. Strategisch gesehen ist es ein Fehler.
Das Problem: Direkter Datenbankzugriff, getarnt als “API”, führt zu Sicherheitsrisiken, hoher Fehleranfälligkeit und bremst die Produktentwicklung aus.
Die Lösung: Echte APIs, die als klar definierte Verträge fungieren. Sie kapseln die Komplexität der Datenhaltung und bieten kontrollierten, sicheren Zugriff über Mechanismen wie Authentifizierung, Autorisierung und Versionierung.
Der Geschäftsnutzen: Gesteigerte Entwicklungsgeschwindigkeit, reduzierte Sicherheits- und Compliance-Risiken und eine stabile, skalierbare Grundlage für datengetriebene Produkte.
Ein Szenario, das die Frage aufwirft
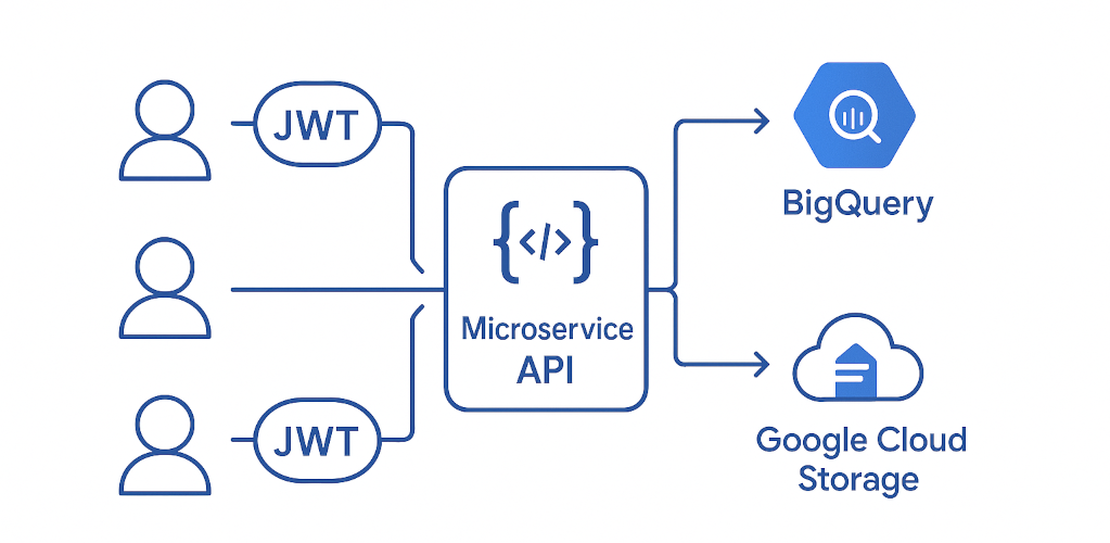
Die Behauptung “Eine Datenbank ist keine API” scheint in Entwicklerkreisen ein ungeschriebenes Gesetz zu sein. Und doch, wenn wir ehrlich sind, sehen wir in der Praxis ständig das Gegenteil. In einem kürzlichen Architektur-Review wurde eine Lösung zur Datenbereitstellung vorgestellt, die genau diese Grenze verwischt:
- „Wir stellen einen direkten Link zum Cloud-Speicher bereit.“
- „Die anfragenden Teams können direkt auf bspw. Tabellen in BigQuery, Databricks Azure SQL etc. zugreifen.“
- „Das ist der schnellste Weg, um Daten zu liefern.“
Diese Ansätze funktionieren. Datenbanken liefern Daten von Punkt A nach Punkt B. Erfüllt eine Datenbank damit nicht die grundlegende Funktion einer API? Die Antwort auf die Frage “… oder doch?” liegt nicht in der technischen Möglichkeit, sondern in den strategischen Konsequenzen.
Lass mich erklären warum diese Abkürzung langfristig zu erheblichen Problemen führt und wie du durch den Aufbau echter APIs eine tragfähige und sichere Datenstrategie etablieren.
Der fundamentale Unterschied: Datenspeicherung vs. Datenkommunikation
Die Antwort auf unsere Ausgangsfrage liegt im fundamentalen Unterschied der jeweiligen Kernaufgaben.
- Datenbanken sind für die effiziente und konsistente Speicherung von Daten optimiert. Ihr Fokus liegt auf Transaktionssicherheit (ACID), Datenintegrität und interner Performance.
- APIs (Application Programming Interfaces) sind für die kontrollierte und standardisierte Kommunikation zwischen Systemen konzipiert. Ihr Fokus liegt auf klaren Verträgen (Contracts), Sicherheit, Versionierung und der Entkopplung von Systemen.
Eine Datenbank kann zwar Daten “liefern”, aber sie wurde nicht dafür gebaut, die komplexen Anforderungen einer kontrollierten, externen Kommunikation zu erfüllen. Eine Datenbank als API zu missbrauchen, ist, als würde man einen LKW-Motor in ein Familienauto einbauen: Er mag die Räder antreiben, aber das gesamte System ist instabil, unsicher und nicht für diesen Zweck gedacht.
Die geschäftlichen Risiken direkter Datenbankzugriffe
Wenn die Grenzen zwischen Datenspeicherung und Datenzugriff verschwimmen, entstehen vier zentrale Risikobereiche:
1. Hohe Kopplung und verlangsamte Entwicklung
Wenn Clients direkt auf die Datenbankstruktur zugreifen, ist jede Änderung an dieser Struktur (z.B. das Umbenennen einer Spalte) ein “Breaking Change”. Dies führt zu einem hohen Koordinationsaufwand, fehleranfälligen Anpassungen bei allen abhängigen Systemen und verlangsamt somit die gesamte Produktentwicklung.
2. Unkontrollierte Sicherheitslücken
Ein direkter Zugriff über einen Link oder eine Tabellenfreigabe umgeht etablierte Sicherheitsmechanismen. Es fehlt eine granulare Kontrolle darüber, welcher Nutzer oder welches System auf welche spezifischen Daten zugreifen darf. Dies öffnet die Tür für unbefugte Datenzugriffe und potenzielle Datenschutzverletzungen.
3. Fehlende Nachvollziehbarkeit (Auditability)
Wer hat wann auf welche Daten zugegriffen? Bei direkten Datenbankzugriffen sind diese Fragen oft nur schwer oder gar nicht zu beantworten. Das Fehlen von Audit-Logs stellt ein erhebliches Compliance-Risiko dar, insbesondere im Kontext von DSGVO oder anderen regulatorischen Anforderungen.
4. Instabile Systeme durch fehlende Versionierung
Ohne eine explizite API-Versionierung sind Updates unvorhersehbar. Teams, die die Daten nutzen, werden von Änderungen überrascht, was zu Systemausfällen und einem Vertrauensverlust in die Datenplattform führt.
Die Lösung: Die API als strategischer Vertrag
Eine echte Data API ist mehr als nur eine technische Schnittstelle; sie ist ein Vertrag zwischen dem Datenanbieter und dem Datenkonsumenten. Dieser Vertrag definiert klar die Spielregeln für den Datenaustausch.
| Eigenschaft | Direkter Datenbankzugriff | Echte API |
|---|---|---|
| Sicherheit | Vage Berechtigungen auf Tabellenebene | Detaillierte Rechte pro Nutzer/Rolle (JWT) |
| Vertrag | Implizit (Datenbank-Schema) | Explizit (OpenAPI/Swagger-Spezifikation) |
| Kopplung | Hoch (direkte Abhängigkeit) | Gering (Abstraktion der Datenquelle) |
| Versionierung | Nicht vorhanden | Standardisiert (/v1/, /v2/) |
| Monitoring | Eingeschränkt | Detaillierte Metriken & Logs pro Request |
| Lebensdauer | Unbegrenzt | Zeitlich begrenzt (Time-to-Live, TTL) |
Vom Konzept zur Praxis: Die API-Eigenschaften entschlüsselt
Die Tabelle zeigt die Unterschiede klar auf, aber wie sehen diese in der Praxis aus? Die folgenden Beispiele sind bewusst einfach gehalten und stellen eine von vielen Möglichkeiten dar, diese Prinzipien umzusetzen. Diese verdeutlichen den Unterschied zwischen einem riskanten Ad-hoc-Ansatz und einer robusten API-Strategie.
1. Sicherheit: Alles-oder-Nichts vs. Gezielter Zugriff
So nicht (Alles-oder-Nichts): Ein langlebiger Schlüssel mit weitreichenden Rechten wird weitergegeben. Jeder, der den Schlüssel hat, hat quasi Vollzugriff.
# Ein statischer, mächtiger Datenbank-Verbindungsstring
db_access = {
"db_connection": "postgres://user:password@host:port/database"
}
Problem: Einmal kompromittiert, ist dieser Schlüssel eine permanente Sicherheitslücke.
So geht’s (Gezielter Zugriff): Die API agiert als Torwächter. Die API authentifiziert den Nutzer und gibt ein kurzlebiges Token zurück, das nur für eine ganz bestimmte Anfrage gültig ist.
# API-Antwort mit einem zeitlich begrenzten Token
access_response = {
"access_token": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...",
"token_type": "Bearer",
"expires_in": 300, # Gültig für 5 Minuten
"scope": "read:customers_de" # Darf nur deutsche Kunden lesen
}
Vorteil: Die API erzwingt das Need-to-know-Prinzip. Der Zugriff ist zeitlich und inhaltlich streng limitiert.
2. Vertrag: Implizit vs. Explizit
So nicht (Impliziter Vertrag): Der Client rät, wie die Daten aussehen, indem er direkt auf die Datenbank schaut. Ändert sich eine Spalte, bricht der Client.
So geht’s (Expliziter Vertrag): Die API liefert einen klaren Vertrag, der die Struktur und den Zugriffsweg definiert. Der Client muss sich nicht um die Details der Datenquelle kümmern.
# API-Antwort, die einen klaren Datenvertrag darstellt
contract_response = {
"access_method": "download_url",
"url": "https://api.example.com/data/export-123.csv",
"schema": {
"customer_id": "string",
"order_value": "number",
"order_date": "date"
},
"expires_at": "2025-06-21T20:15:00Z"
}
Vorteil: Klarheit und Stabilität. Der Client weiß genau, welche Felder er erwarten kann und wie er darauf zugreift, unabhängig von der zugrundeliegenden Datenbank.
3. Kopplung: Hoch vs. Gering
So nicht (Hohe Kopplung): Der Client-Code ist voll mit Logik für eine spezifische Datenbank.
# Client-Code ist an BigQuery gekoppelt
from google.cloud import bigquery
client = bigquery.Client()
results = client.query("SELECT * FROM `my_dataset.my_table`")
Problem: Bei einem Wechsel der Datenbank (z.B. zu Snowflake) muss der Client-Code komplett umgeschrieben werden.
So geht’s (Geringe Kopplung): Der Client fragt die API nach dem Zugriffsweg und dem Schema. Die API liefert eine Anleitung, wie auf die Daten zuzugreifen ist, ohne dass der Client die internen Details kennen muss.
import requests
# 1. Client fragt die API nach dem Datenzugriff
response = requests.get('https://api.example.com/v1/data-access/customers_de')
access_info = response.json()
# 2. API antwortet mit den Metadaten für den Zugriff
# access_info sieht jetzt so aus:
access_info = {
"access_method": "bigquery_view",
"projectId": "your-gcp-project",
"datasetId": "secure_views_for_clients",
"viewId": "view_user456_customers_de",
"schema": [
{"name": "customer_id", "type": "STRING"},
{"name": "customer_name", "type": "STRING"}
],
"expires_at": "2025-06-21T21:00:00Z"
}
# 3. Der Client nutzt diese Infos, um die Daten abzufragen.
# Der eigentliche BigQuery-Code wäre hier, aber er nutzt dynamisch
# die von der API erhaltenen Informationen.
Vorteil: Die API behält die volle Kontrolle. Die API kann die Datenquelle jederzeit ändern oder den Zugriff widerrufen. Der Client ist nur an den API-Vertrag gekoppelt, nicht an eine spezifische Datenbanktabelle.
4. Versionierung: Nicht vorhanden vs. Standardisiert
So nicht (Keine Versionierung): Ein Feldname wird einfach geändert. Alle Clients, die das alte Feld nutzen, brechen.
# Gestern funktionierte das:
import requests
response = requests.get('/customers/123')
old_data = response.json() # {"name": "Max Mustermann"}
# Heute bricht es:
response = requests.get('/customers/123')
new_data = response.json() # {"fullName": "Max Mustermann"}
# Der Client sucht nach "name" und findet es nicht mehr!
So geht’s (Standardisierte Versionierung): Änderungen werden in einer neuen Version eingeführt. Alte Clients funktionieren weiter.
# Version 1 funktioniert weiterhin:
v1_response = requests.get('/v1/customers/123')
v1_data = v1_response.json() # {"name": "Max Mustermann"}
# Version 2 bietet neue Features:
v2_response = requests.get('/v2/customers/123')
v2_data = v2_response.json() # {"fullName": "Max Mustermann", "contact": {...}}
Vorteil: Stabilität und Planbarkeit. Teams können auf die neue Version umsteigen, wenn sie bereit dafür sind.
5. Lebensdauer: Unbegrenzt vs. Zeitlich begrenzt
So nicht (Unbegrenzte Lebensdauer): Ein Link oder Schlüssel ist für immer gültig.
# Gefährlich: Permanent gültiger Zugriff
permanent_access = "https://api.example.com/data?access_key=PERMANENT_KEY"
So geht’s (Zeitlich begrenzt): Jeder Zugriff hat ein klares Ablaufdatum.
# Sicher: Zeitlich begrenzter Zugriff
secure_access = {
"download_url": "https://api.example.com/data/export.csv?token=...",
"expires_at": "2025-06-21T20:15:00Z"
}
Vorteil: Das Zeitfenster für Missbrauch wird drastisch reduziert.
Zusammenfassung
Eine robuste Data API ist ein Vertrag, kein Datenlieferant. Diese agiert als intelligenter Verwalter, der für jede Anfrage eine sichere, temporäre Anleitung zum Datenabruf aushändigt. Die drei vorgestellten Patterns (Authorized Views, Signed URLs, Temporäre Tokens) sind konkrete Umsetzungen dieses Prinzips.
Der Kern: Gib niemals direkten, permanenten Zugriff auf Rohdaten. Kontrolliere jeden Zugriff durch zeitliche Begrenzung, granulare Berechtigungen und explizite Verträge.
Wie starte ich?
Wenn du nur eine einzige Änderung vornehmen kannst, dann diese: Implementiere ein Ablaufdatum für jeden Datenzugriff.
Egal ob Link, Token oder View-Berechtigung – nichts sollte für immer gültig sein. Dieser einfache Schritt verhindert, dass alte Zugriffe zu permanenten Sicherheitslücken werden und ist der erste Schritt weg vom Daten-Chaos hin zu einer kontrollierten API-Strategie.
Fazit: Das ist ein möglicher Ansatz
Also, ist eine Datenbank eine API? Nein.
Der Versuch, sie als eine zu missbrauchen, ist eine Abkürzung, die in technischen Schulden und Sicherheitslücken endet. Die gezeigten Beispiele sind bewusst vereinfacht und stellen eine von vielen Möglichkeiten dar, die beschriebenen Prinzipien umzusetzen.
Es geht nicht darum, es genau so zu machen, wie hier gezeigt. Es geht darum, die verschiedenen Punkte zu erfüllen: Sicherheit durch zeitliche Begrenzung, explizite Verträge statt impliziter Abhängigkeiten, lose Kopplung statt Vendor-Lock-in, Versionierung für Stabilität und detaillierte Logs für Nachvollziehbarkeit.
# Ein möglicher Ansatz: strukturierte Anleitung statt direkter Zugriff
data_access_payload = {
"access_method": "bigquery_view", # Oder "signed_url", "temp_token", etc.
"details": {
"projectId": "your-gcp-project",
"datasetId": "secure_views_for_clients",
"viewId": "view_user456_customers_de"
},
"schema": [
{"name": "customer_id", "type": "STRING"},
{"name": "customer_name", "type": "STRING"}
],
"expires_at": "2025-06-21T22:30:00Z" # Das Wichtigste: Zeitbegrenzung!
}